How does funnelback index pages which load asynchronously? I.e. the page loads but content loads in batches after the initial page has loaded. Is there any configuraiton which can control how Funnelback works with such pages?
Hi Jon,
The short answer is that Funnelback will only deal with the content that is returned when the request for the page is made. Funnelback doesn’t run any Javascript code - when Funnelback crawls it will see what a user sees if they are browsing with Javascript disabled.
If you want Funnelback to index the full content of the page you will need to make some allowance for the full content to be returned to Funnelback (eg. by checking the user agent) when the page is requested.
Hi,
I just wanted to check if this is still the case?
As two years is a long time in web.
I’ve not noticed anything in the documentation so I suspect it possibly is.
(We were looking to crawl web applications built with Angular)
Thanks!
Hey,
I’m afraid nothing has changed on this front.
However it’s not completely impossible - we’ve done some experiments and had some success crawling a JS generated site using a proxy that is basically a headless browser which processes the Javascript and returns the resulting html.
A big drawback of this approach though is the speed of crawling and the fact that you’ll need to set up a bunch of other infrastructure to be able to achieve it.
regards
Also note that there could be risks in doing this as Javascript is one way sites can prevent a crawler from submitting a form that does something destructive (like delete a page) so whatever you do proceed with caution.
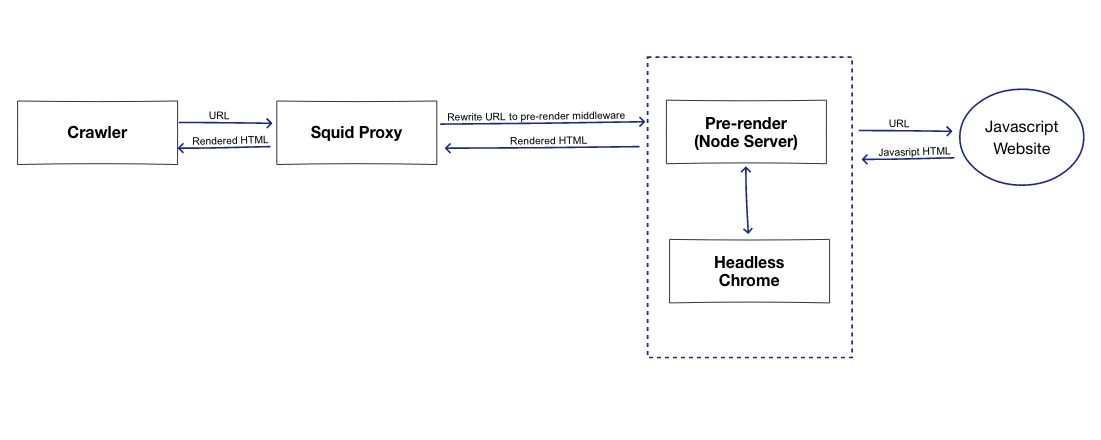
We’ve had some success using some of offerings from prerender.io.. one via the pages served up by their hosted service and if you want to set up your own infrastructure via prerender (github), using Squid as a proxy.
A very high level view of the solution below: